資料來源#
摘要#
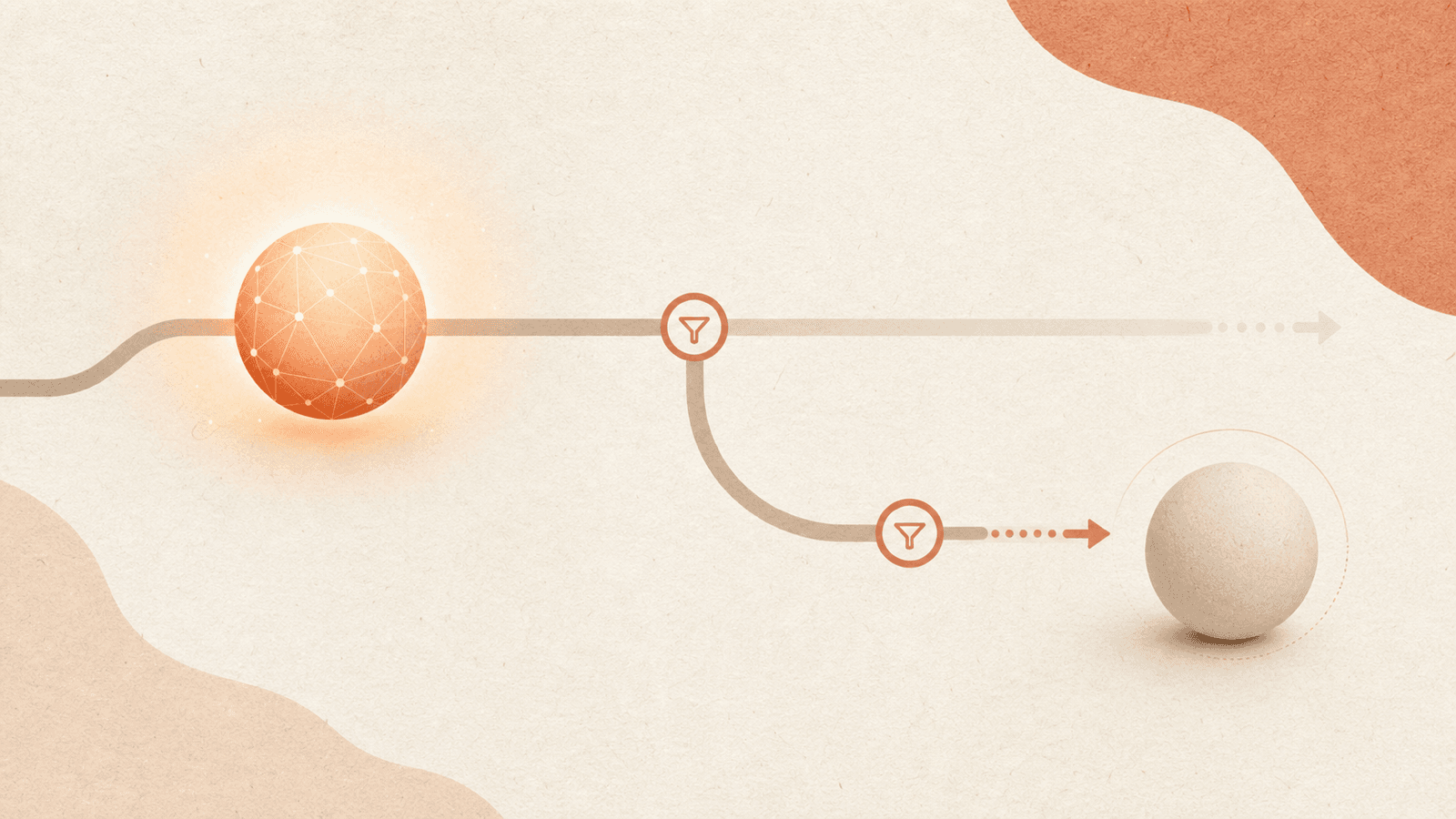
這項防護架構讓 Anthropic 能夠向大眾發布 Mythos-class 模型供一般使用:當獨立的 AI 分類器偵測到高風險雙重用途領域(網路安全、生物與化學,或蒸餾)的查詢時,回應會自動由能力較弱的模型——Claude Opus 4.8——處理,而不是由 Fable 5 予以拒絕。 每當此情況發生時,都會告知使用者。Anthropic 的說法是:「退回到 Opus 的回應,其體驗遠優於直接拒絕。」超過 95% 的 Fable sessions 完全沒有觸發退回;分類器經過保守的調校(它們「有時會捕捉到無害的請求」,在「不到 5% 的 sessions」中觸發),接受偽陽性作為快速且安全發布的代價。
這是防護光譜上一個截然不同的定位。Mythos Preview 被完全限制(僅限預覽);Opus 4.7 在訓練期間被差異化降低了網路安全能力,並且在推論時進行阻擋;Fable 5 則在模型中保留了完整的能力,但介入了一個分類器,在遇到高風險主題時替換為較弱的模型。其能力在超過 95% 的良性情況下得以保留,並在其他情況下被繞道處理。
為什麼是「退回,而非拒絕」#
其動機是 uplift(能力提升):Mythos-class 模型可能會為惡意行為者提供「他們無法從其他來源獲得」的網路/生物協助。而且許多進階用途都具有雙重用途——同一個查詢對防守方或研究人員是有益的,而對攻擊者而言卻是危險的。一刀切的拒絕既會帶來糟糕的使用者體驗,而且因為洩露了哪些查詢是「危險的」,還會成為一種資訊訊號。退回到 Opus 4.8——其本身就是一個能力極強的模型——能實現優雅降級:使用者在被標記的主題上仍能獲得有能力的回答,只是不是 Mythos-class 等級的回答。
三個分類器領域#
- 網路安全。廣泛涵蓋 exploitation(漏洞利用)和攻擊性網路任務(偵察、發現、橫向移動——參見 LLM-Driven Vulnerability Research)。在阻擋模式評估中,「我們的分類器阻止了 Fable 在這些任務上取得任何進展」。一個外部合作夥伴發現 Fable 5 的網路安全防護是所有受測模型中最穩健的(包括 Opus 4.8 和 4.7):無論是否使用 30 種公開 jailbreak 技術中的任何一種,Fable 針對網路攻擊規劃、exploit 開發或防禦規避等有害單輪請求的配合度皆為零。
- 生物與化學。以前 Anthropic 僅阻擋了狹義的生物武器查詢;考慮到資源豐富的惡意行為者以及模型不斷增長的現實世界科學能力,這「已不再足夠安全」。實際案例:預測基因修飾如何影響 adeno-associated virus (AAV) capsid assembly——Mythos-class 模型僅憑藉生物學推理,在未接受該任務訓練的情況下,表現便超越了專用的 protein-language models(參見 Autonomous Scientific Discovery)。由於有助於基因治療的相同技能也可能被用於設計危險的病毒,Fable 目前在大多數生物/化學請求中會退回到 Opus 4.8——這是有意採取的過度寬泛策略,稍後會再收窄。
- 蒸餾。被標記為企圖將 Fable 5 的能力蒸餾到競爭對手模型中的請求(這是一個已知的規模化萃取威脅,特別是針對「專制國家」)會退回到 Opus 4.8。其風險是在沒有相應安全防護的情況下,間接擴散了接近前沿的能力。
強韌性(紅隊演練)#
分類器擴展了 Anthropic 之前的 constitutional-classifiers 路線(參見 Agentic Prompt Injection),具有更廣泛的覆蓋範圍,並針對 jailbreaks 進行了壓力測試:
- 一次外部 bug bounty 在超過 1,000 小時的測試中,沒有產生任何通用 jailbreaks。
- 外部紅隊組織「到目前為止,未能在長週期的 agentic 任務中發現任何通用 jailbreaks」——儘管 UK-AISI 在短暫的初始視窗期內取得了一項進展。
- Anthropic 承認「完全防止通用 jailbreaks 可能是不可能的」;其目標是讓任何殘留的攻擊「足夠緩慢且昂貴,以便我們能夠在大規模使用之前偵測並阻止它們」——這是一種套用於防護機制本身的 tedious-vs-impossible 框架。
一個通用的 jailbreak 被定義為任何能讓使用者與模型互動「就如同其安全防護不存在一樣」的 prompt/script/harness,這與僅在狹窄上下文中有效的次要 jailbreaks 相對。
30 天數據保留政策#
與安全防護相結合:Anthropic 現在要求對所有 Mythos-class 流量進行 30 天的數據保留(第一方與第三方,包括企業客戶)。該數據僅用於安全目的——防範複雜/新型攻擊(新的 jailbreaks、跨請求攻擊)並減少偽陽性——不用於訓練,在幾乎所有情況下都會記錄人工存取並在 30 天后刪除。因此,能力門檻不僅改變了模型的防護欄,也改變了圍繞其的數據處理合約。
它所處的位置#
RSP 決定了哪些能力需要進行門檻管控(網路安全、CB、AI-R&D、對齊失效);而這項架構則是針對一般發布的模型,在推論時如何實作網路/生物管控門檻。它是訓練時和政策層面煞車的部署時補充——也是對 Mythos Preview 所遺留之開放問題的營運解答:你如何在不輸出 uplift(能力提升)的前提下,向所有人提供 Mythos-class 的能力?
相關連結#
- Agentic Prompt Injection —— Fable 的分類器擴展了此處記錄的 constitutional-classifier 路線;jailbreak 穩健性是共同的對抗性架構
- Claude Code Auto Mode —— 在工具呼叫邊界上相同的分類器管控概念;本頁面將其應用於查詢邊界,並且替換成較弱的模型而非直接阻擋
- Responsible Scaling Policy Evaluations —— RSP 決定了必須對哪些內容進行管控;這是推論時的機制,而 Mythos-class 超過風險閾值正是迫使其發生的原因
- LLM-Driven Vulnerability Research —— 網路安全分類器所中和的網路能力;Fable 阻擋了在攻擊性網路任務上的「任何進展」
- Autonomous Scientific Discovery —— 生物/化學分類器所管控的生物能力;AAV 雙重用途的範例是其動機實例
- Claude Fable 5 —— 搭載這些安全防護出貨的模型
- Claude Mythos 5 —— 解除了這些安全防護的模型;定義這兩個 SKUs 的對比
- Claude Opus 4.8 —— 退回的目的地模型;「遠優於拒絕」的體驗建立在其本身就具有極高能力的基礎上
- Impossible, Not Tedious (Design Test) —— 安全防護本身的成功標準:使 jailbreaks 足夠緩慢且昂貴,以便在大規模使用之前被捕獲
待解決的問題#
- 超過 95% / <5% 的數據是在 session 等級;對於合法的安全研究人員與生物學家來說,其偽陽性率是多少?他們的良性查詢恰恰是最有可能觸發保守分類器的查詢。
- 退回而非拒絕保留了 UX,但這意味著用於安全/生物相關工作的真實一般存取模型是 Opus 4.8,而非 Fable——這是否會在信任存取計劃開放之前,悄悄限制了 Fable 對整個專業領域的價值?
- UK-AISI 針對「通用 jailbreak 的進展」已被揭露但未被量化——且發布後的存取暫停(參見 Claude Fable 5)引出了一個問題:是否是防護機制的失敗迫使了這一決定。
- 在被標記的主題上切換到較弱的模型是否會創建一個可利用的 oracle(探測哪些查詢會觸發退回,以繪製分類器的邊界)?
資料來源#
- Claude Fable 5 and Claude Mythos 5 —— §"Claude Fable 5's new safeguards"(安全分類器;網路/生物/蒸餾覆蓋範圍;紅隊演練;30 天數據保留)
Cited by 12
- Agentic Prompt Injection
Direct and indirect injection of malicious instructions into an agent; LLMs cannot reliably distinguish information fro…
- Anthropic
AI safety company / vendor of Claude; mission-as-tiebreaker culture; ~30–40 PMs across teams; Mike Krieger leads Labs r…
- Autonomous Scientific Discovery
Mythos-class models now conduct novel science with limited human input — autonomous protein/drug design (~10× faster, m…
- Claude Code Auto Mode
Claude Code permission mode using a classifier to auto-approve safe tool calls and block risky ones; middle ground betw…
- Claude Fable 5
Anthropic's first generally-available Mythos-class model (June 2026) — state-of-the-art on nearly all benchmarks; the s…
- Claude Mythos 5
The safeguards-lifted form of Claude Fable 5 (June 2026): same underlying Mythos-class model, deployed through Project…
- Claude Opus 4.8
Anthropic's most capable general-access model (May 2026); upgrade on Opus 4.7 in SWE/agentic/knowledge work; does not a…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- Governance & Workforce
Map of Content for the governance-workforce domain — 11 concepts. Curated entry point; see Home for all domains.
- Mythos Model
Anthropic preview-tier frontier model and the first member of the Mythos-class tier (above Opus); gated for safety, use…
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._
- Responsible Scaling Policy Evaluations
Anthropic's RSP gates deployment on pre-release capability evaluations in CBRN, automated AI R&D, and high-stakes misal…
Related articles
- Anthropic
AI safety company / vendor of Claude; mission-as-tiebreaker culture; ~30–40 PMs across teams; Mike Krieger leads Labs r…
- Claude Mythos 5
The safeguards-lifted form of Claude Fable 5 (June 2026): same underlying Mythos-class model, deployed through Project…
- Claude Opus 4.8
Anthropic's most capable general-access model (May 2026); upgrade on Opus 4.7 in SWE/agentic/knowledge work; does not a…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- Responsible Scaling Policy Evaluations
Anthropic's RSP gates deployment on pre-release capability evaluations in CBRN, automated AI R&D, and high-stakes misal…