資料來源#
摘要#
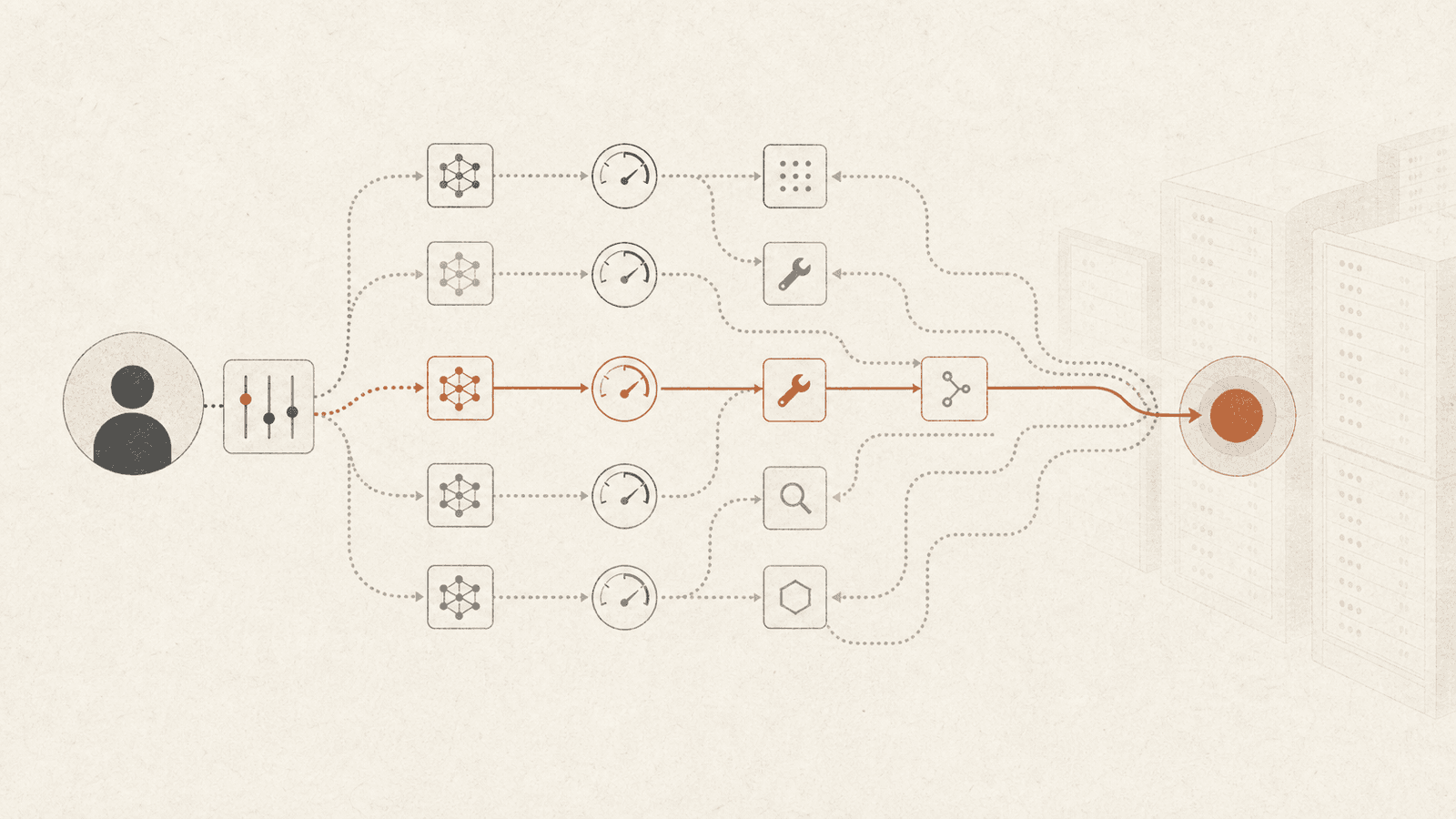
Hua et al.(AgentOpt, 2026)提出的一種 framing:把 agentic workflows 的 client-side optimization,也就是開發者可控的決策,例如要把哪個 model 分配給每個 pipeline role、API budget allocation,以及 tool routing,和過去主導 LLM serving 系統研究的 server-side techniques(caching、scheduling、speculative execution、load balancing)分開。核心 empirical claim 是:model selection 必須在完整 pipeline combinations 的層級評估,而不是按 per-role in isolation 評估,並且它是最主要的 efficiency lever:在 accuracy 相同時,跨 benchmarks 的最佳與最差 combinations 之間,cost gaps 從 13× 到 32× 不等,大到不是 server-side optimizations 能追回來的程度。
細節#
Server-Side vs. Client-Side#
Server-side systems(vLLM、SGLang、Autellix、ThunderAgent、Continuum、AIOS)用 throughput、tail latency、cluster utilization 這類目標,為許多 users 最佳化 provider infrastructure。這些目標是 generic 的,因為 provider 看不到開發者具體的 utility function。Client-side optimization 則是在一個 specific workflow 的層級運作,針對 quality、cost、latency 上的 application-specific utility 最佳化;startup 的 coding assistant 和 clinical-support system 有互不相容的 preferences,不能從 system-level signals 推論出來。
client control 下的資源:
- Foundation model pool — 可用的 API 與 local models
- Model-to-role assignment across planners, solvers, critics, retrievers
- Tool invocation policy — local vs. remote,以及何時 skip
- API budget per step
- Application-level batching, caching, scheduling
為什麼 Model Selection 是 First-Class#
Model selection 位於其他所有 client-side optimization 的 upstream:caching、routing heuristics、speculative execution 都是在既定 model assignment 的條件下運作。選錯 combination,下游 optimization 再怎麼做也補不上差距。
empirical evidence 很驚人。在 BFCL 上,Qwen3 Next 80B 以 32× lower cost 達到與 Claude Opus 4.6 相同的 accuracy。在 MathQA 上,comparably-accurate combinations 之間也存在 24× gaps。
Combo Abstraction#
這篇 paper 的關鍵 conceptual contribution。在傳統 LLM routing 中,每個 query 會根據預估 difficulty,被分配給較便宜或較強的 model,也就是 per-call decisions。在 multi-step agents 中,routing decisions 是 coupled across stages:某個 role 裡 model 的 behavior,會改變後續 roles 看到的 intermediate state。會 delegate 給 tool 的 planner,和從 parametric knowledge 直接回答的 planner,會創造出不同的 downstream work。
結果是:optimization 的單位是完整 combination $\mathbf{c} = (m_1, \dots, m_H) \in \mathcal{M}^H$,而不是 per-role best。Performance rankings 不會乾淨地跨 roles 轉移;一個強大的 standalone model 可以是優秀 solver,卻是糟糕 planner。
paper 中的 canonical illustration,HotpotQA:
- Claude Opus 4.6 is the worst planner across 81 combinations — 當它被用作 planner 時,常常直接從 parametric knowledge 回答,繞過 solver 的 search tools。
- Ministral 3 8B is the best planner,因為它會可靠地 delegate 給 downstream solver。
- Ministral(planner)+ Opus(solver)→ 74.27%;Opus(planner)+ Opus(solver)→ 31.71%。
這和 Scale-Dependent Prompt Sensitivity 描述的 overthinking / overelaboration phenomenon 是同一件事,只是這裡呈現為 routing failure,而不是 prompt-engineering failure。
形式化為 Black-Box Optimization#
給定 pipeline roles $H$ 與 candidate set $M$,combination space 是 $|M|^H$,也就是 exponential。utility function
$$J(\mathbf{c}) = \mathrm{PERF}(\tau(\mathbf{c})) - \lambda_c,\mathrm{COST}(\tau(\mathbf{c})) - \lambda_\ell,\mathrm{LATENCY}(\tau(\mathbf{c}))$$
被視為 unknown black-box,因為 cross-stage interactions 是 task-dependent,且無法 analytically tractable。
Search Algorithms#
AgentOpt 實作了八種 selectors,並共享同一個 execution substrate:
- Arm Elimination(best-performing)— multi-armed bandit,會 prune dominated combinations。在 3/4 benchmarks 上,相較 brute force,用 24–67% less evaluation budget 就能恢復接近 optimal accuracy。
- Epsilon-LUCB — confidence-bound bandit
- Threshold Successive Elimination
- Bayesian Optimization
- 另有 hill climbing、random search,以及 brute-force baselines
所有 selectors 都共享同一個 API,因此 strategies 可以互換,而不用碰 agent code。
Framework-Agnostic Interception#
systems mechanism:在 HTTP transport layer patch httpx.Client.send 與 httpx.AsyncClient.send。每個 call 到(datapoint, combination)的 attribution 使用 Python contextvars。這避開了 per-framework SDK adapters;可跨 Langgraph、AutoGen、OpenClaw、Claude Code,以及任何底層使用 httpx 的 agent 運作。
runtime 也處理 response caching(相同(combo, datapoint)pair 的 re-runs 不會再次花掉 API budget)以及 parallel execution(例如 max_concurrent=20)。
Output:一個 SelectionResults object,暴露(performance, cost, latency)上的 Pareto frontier,並提供 CSV export 與部署用的 YAML configuration export。
Policy 與 Execution 的分離#
Selectors(下一步要 evaluate 什麼)和 runtime(如何 execute、track、attribute、cache)彼此分離。這種 separation 讓八個 algorithms 能共享 benchmarks;search 才是唯一變數。
野外的 Manual Levers#
AgentOpt formalizes 的 client-side levers(model assignment、budget、caching、batching)在 production agent tools 中已經以 user-facing CLI commands 出現。Hermes Agent 最明確:
| Hermes lever | AgentOpt analog |
|---|---|
/model(mid-session model switch) | combo space 中的 per-role model assignment |
/compress(summarize conversation) | application-level caching / context-budget management |
/usage, /insights | 對 AgentOpt utility 使用的同一組 cost/latency/perf signals 做 observability |
delegate_task(parallel subagents with isolated contexts) | 具有 independent combos 的 sub-pipeline assignment |
Bounded MEMORY.md(~2,200 chars)、USER.md(~1,375 chars) | persistent context 上的 explicit budget envelope |
| Prompt-cache discipline(avoid mid-session model/system-prompt changes) | 讓 per-session combo selection 穩定的 cache-stability constraint |
意義:這些 levers 今天已存在於 production tools 中,並由 users 手動操作。AgentOpt 的 contribution 是把同一個 lever space 上的 selection 自動化,而不是引入新 levers。一座 practical bridge 會是讓 AgentOpt selector 根據 benchmark,驅動 Hermes 的 /model switches 做 per-role selection,然後把 resulting combo 寫入 AGENTS.md 以供 deployment。
Hermes documentation 也捕捉到 AgentOpt 的 combo abstraction 隱含依賴的一項 constraint:don't break the prompt cache mid-session。Cache hits 讓 per-message cost 大致保持 constant;mid-session model/system-prompt changes 會 invalidate 它。如果 combo selection 是 per-call 而不是 per-session,expected savings 可能被 cache misses 抹掉;把 AgentOpt findings 推向 production 時,這是值得明講的 deployment hazard。
相關連結#
- Evals as Product Spec — 好的 evals 才能讓 per-role model optimization 可測量
- The Verifiability Thesis — A/B/C/D cost-vs-solve frontier 是在 verifiable rewards 內做 optimization
- Scale-Dependent Prompt Sensitivity — AgentOpt 的 HotpotQA finding(Opus 是最差 planner,因為它繞過 solver)和 Hakim 在 prompt level 記錄的 overthinking / over-elaboration mechanism 是同一件事。一篇 paper 把它呈現為 routing failure,另一篇呈現為 prompt-engineering failure;合在一起,它們暗示 large-model misuse 是一種 systematic failure mode,且有兩種可用 mitigations(route around it,或 constrain output)
- Agent Harness Engineering — client-side optimization 是 harness design 上方的一層:一旦 environment、progress logs、verification loops 就位,combo selection 就會選擇 which models 在該 harness 內運作。JSON feature-list 與 progressive-disclosure patterns 是 AgentOpt 分配的 agents 的 execution substrate
- Claude Code Best Practices — 直接挑戰隱含的「use the strongest model」default。AgentOpt 的 framework-agnostic httpx interception 也和 Claude Code 的
claude -pnon-interactive mode 相容,暗示 Claude Code pipelines 可以被納入 combo optimization - LLM-Driven Vulnerability Research — file-ranking 1–5 pre-pass 與 final validation agent,是 AgentOpt 會自動 search 的東西的 hand-tuned instances。把 vuln-research scaffold 視為 AgentOpt pipeline(planner = file-ranker, solver = bug-finder, critic = validator)是直接 generalization
- LLM-as-Compiler Knowledge Base — wiki 自身的 compile / query / lint phases 可以被 modeled 為 agent pipeline,其中不同 phases 在不同 models 上執行(例如 cheap model 做 index drift checks,strong model 做 cross-reference synthesis)
- Claude Opus 4.7 — HotpotQA planner failure 是在 Opus 4.6 上測得;4.7 的 literal instruction following 可能部分縮小該 gap(需要 re-measurement)。Task budgets(public beta)呼應 AgentOpt 的 budget lever,但屬於 server-side 而非 client-side
- Hermes Agent — production CLI agent,把 AgentOpt lever space(
/model、/compress、delegate_task、bounded memory、prompt-cache discipline)暴露為 user-facing commands;是 AgentOpt selectors 自動驅動 role assignment 的自然 integration target - Symphony — 在 scale 下,ticket-driven orchestration 讓 per-pipeline combo selection 變得 operationally important:在
WORKFLOW.md的 prompt template 裡,依 ticket type(planner vs. solver vs. reviewer)選對 model,就是 per-pipeline budget decision - Codex App Server Protocol —
agent.max_turns、turn/stall timeouts,以及 dynamic-tool-call cost,都是 AgentOpt formalizes 的 budget lever 的 operational instances - Interaction / Background Model Split — multi-model design 的另一條 axis:那裡是 cost-driven 且靜態 per role,這裡是 latency-driven 且動態 per turn
- Ticket-Driven Agent Orchestration — 在 orchestration scale,於
WORKFLOW.md內依 ticket type(planner/solver/reviewer)選對 model,是 combo selection 的 per-pipeline instance - Evolutionary Proof Search — model-per-role 具體化:DeepMind 用 Gemini 3.1 Pro 做 proving,用較便宜的 3.0 Flash 做 rating;這是在一個 agent 內明確的 cost/quality combo
- AI-Driven Formal Proof Search — A/B/C/D solve-rate-vs-cost Pareto curves 是 AgentOpt formalizes 的同一種 cost/quality optimization;在這裡,cheaper config 往往勝出(Agentic Loops Overtake Bespoke Systems)
衍生內容#
- When to Use Claude Opus 4.6 for Work — 從 HotpotQA planner/solver results 與 BFCL 32× cost-match finding 推出的 deployment rules
- Opus 4.6 → 4.7 Changes and Multi-Agent Coding Considerations — 套用到 Opus 4.7 multi-agent coding team 的 role-based model selection principles
開放問題#
- combination-level optimization 如何和 continual model releases 互動?如果 Claude Opus 4.7 下個月 ship,完整 Pareto frontier 是否需要 re-running,還是 warm-started bandits 能便宜地 adapt?
- pipeline depth 到哪個程度時,即使對 Arm Elimination 而言,combinatorial search 也會變得 intractable?paper 測到約 81 combinations;具有 5+ roles 且每個 role 有 10+ candidate models 的 production pipelines 會遠遠超過那個規模。
- 「weak planner + strong solver」pattern 會 generalize,還是只特定於 HotpotQA 的 delegation dynamic?Recommender-critic、drafter-editor、retriever-generator topologies 可能反過來。
- tool environment 改變時,正確的 re-evaluate 方式是什麼?AgentOpt 假設 fixed tools;新增或移除 tool 可能讓整個 frontier 失效。
- 是否存在便宜的 per-call classifier,能預測某個 query 上哪個 combination 會贏,從而完全避免 combo-level evaluation?
資料來源#
Cited by 22
- Agent Control Plane Patterns: Tickets, Loops, Specs, and Memory Files
Layered agent control-plane synthesis: tickets as durable work graph, loops as execution primitive, specs/context files…
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Agentic Loops Overtake Bespoke Systems
DeepMind's *basic* Ralph-loop agent matched its bespoke evolutionary+AlphaProof system as the LLM improved; the bitter…
- AI-Driven Formal Proof Search
LLM generates Lean, compiler verifies every step → eliminates hallucination; DeepMind resolves 9/353 Erdős + 44/492 OEI…
- AlphaProof Nexus
DeepMind framework for LLM-aided Lean proof generation; four agents (basic→full-featured); proof-sketch + EVOLVE-BLOCK…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Claude Opus 4.7
GA frontier model from Anthropic; direct upgrade to 4.6 at same price; literal instruction following, 1.0–1.35× tokeniz…
- Codex App Server Protocol
JSON-RPC stdio protocol for headless Codex sessions: initialize/initialized/thread-start/turn-start handshake, continua…
- Evals as Product Spec
Cat Wu's framing of evals as the emerging core PM skill: ten great evals beats a hundred mediocre; encode what done loo…
- Evolutionary Proof Search
The full-featured agent's mechanism: population DB of proof sketches, Elo via Plackett–Luce/Gibbs, P-UCB selection, LLM…
- Hermes Agent
Nous Research's CLI agent + Gateway daemon (Telegram/Discord/Slack/WhatsApp); AGENTS.md/SOUL.md context split, bounded…
- Interaction / Background Model Split
Dual-model architecture: time-aware interaction model stays present; async background model handles deep reasoning/tool…
- LLM-as-Compiler Knowledge Base
Karpathy's architecture: LLM incrementally compiles raw docs into a persistent interlinked wiki, replacing RAG with a 4…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- AI Engineering & Agent Tooling
Map of Content for the ai-engineering domain — 36 concepts. Curated entry point; see Home for all domains.
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._
- Opus 4.6 → 4.7 Changes and Multi-Agent Coding Considerations
4.6→4.7 delta table + six hazards for multi-agent coding teams: role-based model selection, prompt re-tuning, harness i…
- Scale-Dependent Prompt Sensitivity
Large models underperform small ones on 7.7% of standard benchmarks due to overthinking; brevity constraints recover 26…
- Symphony
OpenAI's open-source agent orchestrator (March 2026): turns Linear into a control plane for Codex, per-issue workspace,…
- Ticket-Driven Agent Orchestration
The inversion that makes Symphony work: tickets as units of work (not sessions/PRs), DAG dependencies, agent-extensible…
- The Verifiability Thesis
LLMs automate what you can *verify* as computers automate what you can *specify*; RL verification rewards → jagged peak…
- When to Use Claude Opus 4.6 for Work
Decision rules for Opus 4.6 deployment: solver-not-planner, elaboration-load-bearing tasks, brevity constraints, Pareto…
Related articles
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Scale-Dependent Prompt Sensitivity
Large models underperform small ones on 7.7% of standard benchmarks due to overthinking; brevity constraints recover 26…
- Agent Loop Pattern
`/loop` (cron-scheduled) and Ralph Wiggum (backlog-draining) loops as next-generation agent primitive; AFK execution, p…
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._