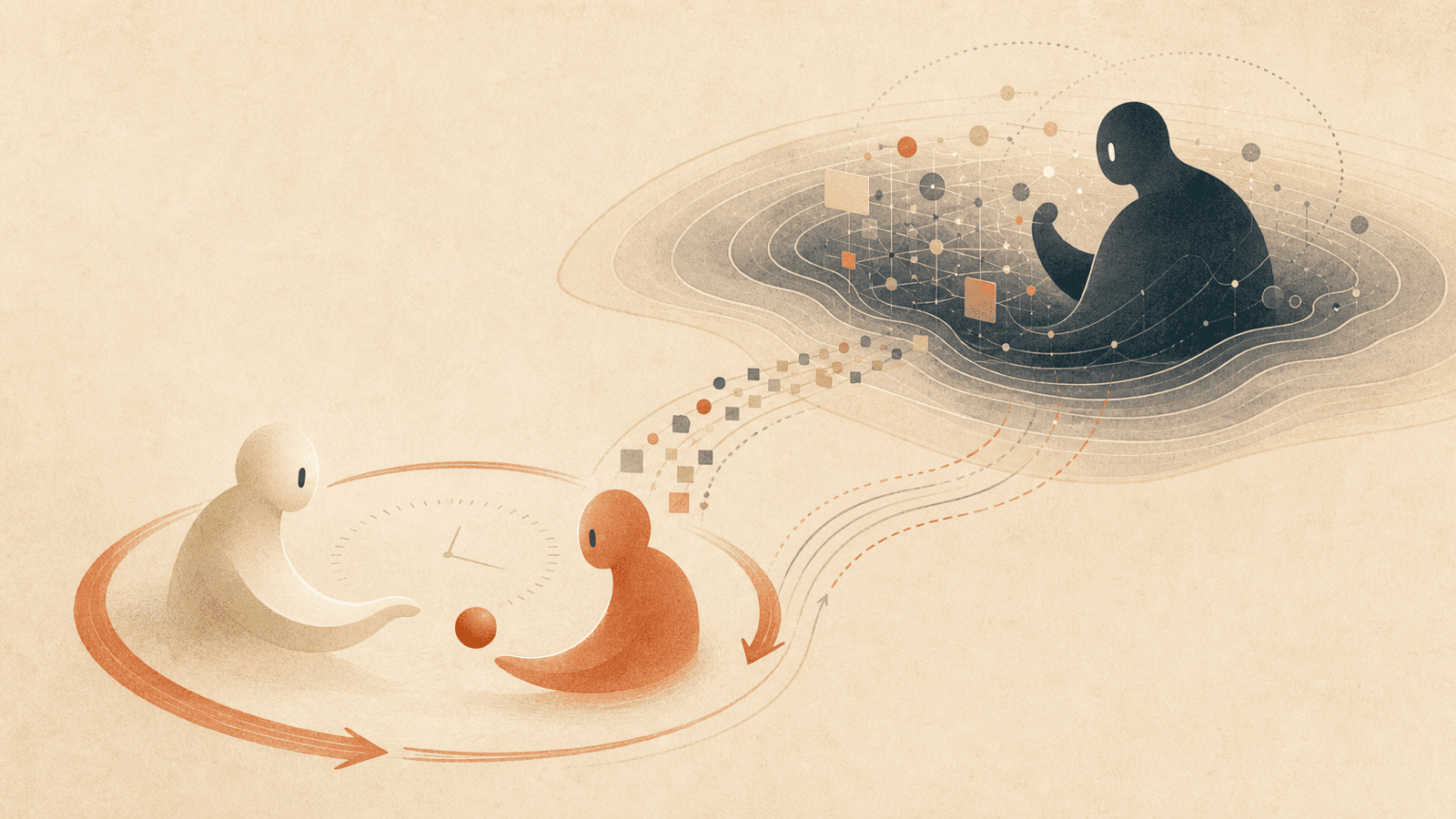
資料來源#
摘要#
Interaction Models 的架構由兩個協作模型組成:
- 一個具時間感知的互動模型,維持即時在場——在持續迴圈中感知並回應(參見 Time-Aligned Micro-Turns);
- 一個非同步背景模型,負責持續推理、工具使用及更長期的工作。
其效益在於:使用者同時獲得即時回應與深度——「以非思考模型的回應延遲,達成推理模型的規劃、工具使用與 agentic 工作流程。」
委派機制#
- 當任務需要的推理深度超出即時可產出的範圍時,互動模型會委派給背景模型,由其非同步執行。
- 交接內容是一個豐富的上下文封包——不是獨立的查詢,而是完整的對話。
- 互動模型全程保持在場——回答後續問題、接收新輸入、維持對話脈絡。
- 背景模型產出結果後會串流回傳;互動模型會在適當時機將更新穿插進對話中——配合使用者當下正在做的事,而非突兀地切換上下文。
兩端皆具智慧#
這並非「笨前端、聰明後端」的設計。互動模型本身「在互動性與智慧基準測試上皆具競爭力」——參見 Interactivity Benchmarks(例如 TML-Interaction-Small 在 Audio MultiChallenge APR 上擊敗所有非思考基線,即使未使用背景 agent;標記 * 的基準測試使用背景 agent 處理推理/工具任務)。
與其他多模型模式的關係#
這是多模型編排中延遲與深度的軸線,有別於:
- Client-Side Agent Optimization 中的角色導向模型選擇(在 agent 圖中依角色分配便宜/昂貴模型)——該分割以成本為驅動且為靜態;此處則以延遲為驅動且逐輪動態調整;
- 三 agent / 全新上下文審查者模式(Deep Modules for Agents、Agent Harness Engineering)——該分割目的是上下文隔離;此處則是為了時間性考量(保持回應 vs. 深度思考)。
開放議題 / 已知限制#
TML 稱背景 agents 為「不可或缺的能力」,且他們「才剛開始探索」——既要將背景 agentic 智慧推向前沿,也要探索背景 agents 如何與互動模型協同運作。
相關連結#
- Interaction Models — 上層概念
- Time-Aligned Micro-Turns — 在背景模型思考時維持互動模型在場的機制
- Interactivity Benchmarks — 標記
*的結果使用背景 agent;展示此分割的貢獻 - Client-Side Agent Optimization — 多模型設計的另一軸線(成本/角色,而非延遲/深度)
- Deep Modules for Agents / Agent Harness Engineering — 為上下文隔離而非延遲所做的多 agent 分割
- Harness Shrinkage as Models Improve — 開放問題:此分割是永久性的,還是在單一模型同時夠快且夠深之前的過渡產物
- Encoder-Free Early Fusion — 架構的另一半(感知/生成端)
- Full-Duplex Interaction — 互動模型保持在場時,並行深度工作的去處
- TML-Interaction-Small — 實作此分割的模型;即使未使用背景 agent 也在智慧基準測試上具競爭力
資料來源#
Cited by 10
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Client-Side Agent Optimization
AgentOpt's framing of developer-controlled agent optimization (model-per-role, budget, routing) as distinct from server…
- Deep Modules for Agents
Ousterhout deep-vs-shallow modules applied to agent-friendly codebases; push-vs-pull instruction delivery; reviewer in…
- Encoder-Free Early Fusion
Multimodal design with minimal pre-processing instead of large standalone encoders: dMel audio embedding, 40×40-patch h…
- Full-Duplex Interaction
Perceive-and-respond simultaneously across modalities; proactive interjection, visual-cue reactions, simultaneous speec…
- Interaction Models
Thinking Machines Lab (May 2026): models that handle audio/video/text interaction natively in real time instead of via…
- Interactivity Benchmarks
FD-bench, Audio MultiChallenge + new TimeSpeak/CueSpeak (proactive audio) and RepCount-A/ProactiveVideoQA/Charades (vis…
- Interaction & Multimodal
Map of Content for the interaction-multimodal domain — 7 concepts. Curated entry point; see Home for all domains.
- Time-Aligned Micro-Turns
The core interaction-model move: input/output as continuous streams in ~200ms interleaved chunks, no turn boundaries; s…
- TML-Interaction-Small
TML's first interaction model: 276B MoE / 12B active, audio+video+text in / text+audio out, 200ms micro-turns, async ba…
Related articles
- Interaction Models
Thinking Machines Lab (May 2026): models that handle audio/video/text interaction natively in real time instead of via…
- Full-Duplex Interaction
Perceive-and-respond simultaneously across modalities; proactive interjection, visual-cue reactions, simultaneous speec…
- Time-Aligned Micro-Turns
The core interaction-model move: input/output as continuous streams in ~200ms interleaved chunks, no turn boundaries; s…
- TML-Interaction-Small
TML's first interaction model: 276B MoE / 12B active, audio+video+text in / text+audio out, 200ms micro-turns, async ba…
- Claude Opus 4.7
GA frontier model from Anthropic; direct upgrade to 4.6 at same price; literal instruction following, 1.0–1.35× tokeniz…