資料來源#
摘要#
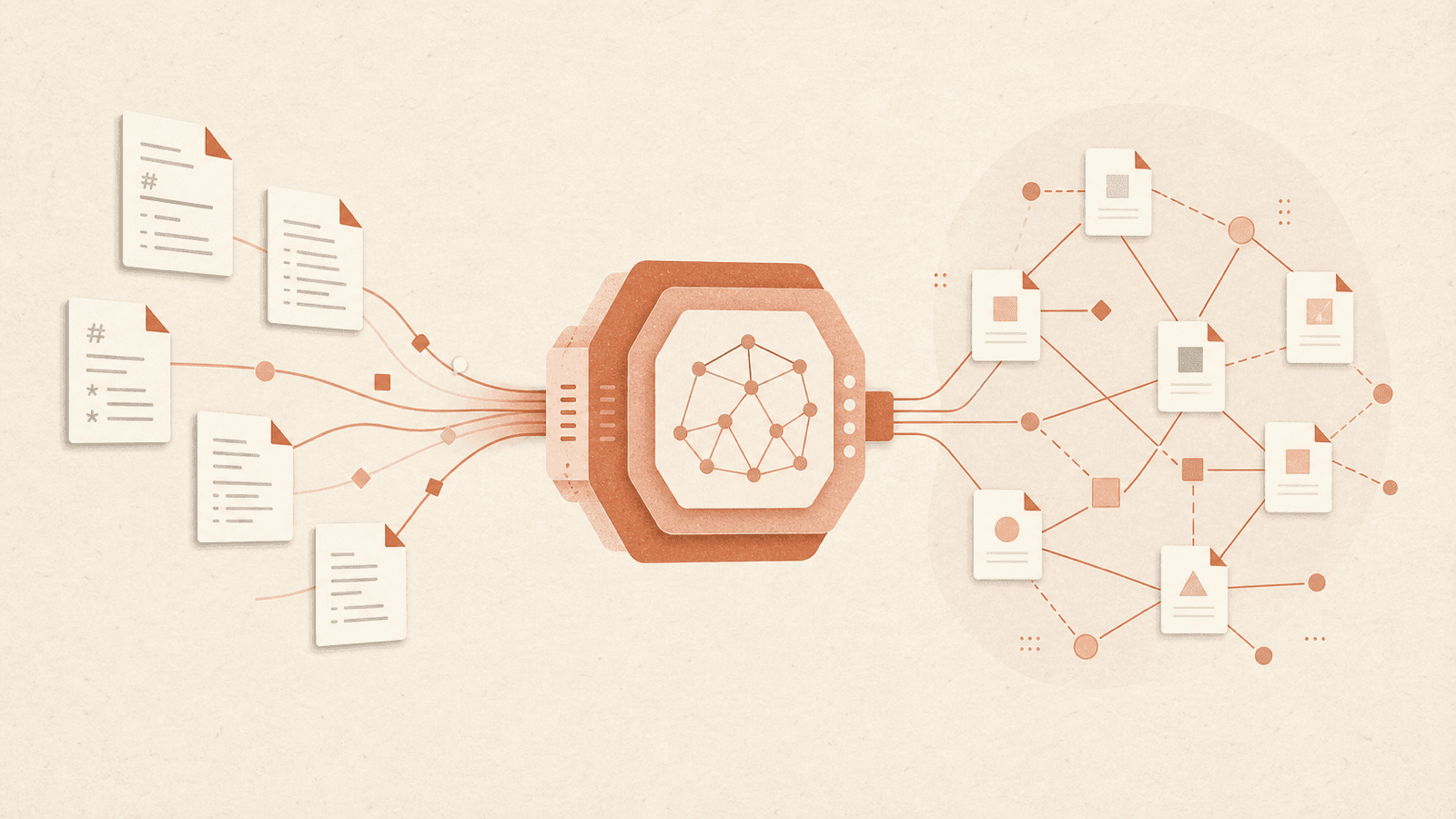
一種由 Andrej Karpathy 首創的架構模式,讓 LLM 扮演編譯器的角色:它讀取原始來源文件,並逐步產出一個結構化、彼此互聯的 markdown wiki。不同於仰賴 embeddings 與向量資料庫的傳統 RAG 系統,這套做法是用 wiki 自身的索引檔與 LLM 的 context window 來做檢索,在個人知識庫的規模下(約 100 篇文章、約 40 萬字)便已足夠。
細節#
四階段流程#
整個系統以一個持續循環的方式運作:
- Ingest(攝取) — 原始內容(透過 Obsidian Web Clipper 擷取的網路文章、論文、儲存庫筆記)以 markdown 檔的形式進入
raw/暫存目錄。 - Compile(編譯) — LLM 讀取
raw/,並建立索引檔(所有文件的摘要)、概念文章(依主題組織,帶有反向連結與交叉引用),以及衍生產物(投影片、圖表、歸檔的查詢答案)。LLM 會自動維護各概念之間的連結圖。 - Query & Enhance(查詢與強化) — 使用者在 Obsidian 中瀏覽 wiki,透過 Q&A agent 提出研究問題,或用 CLI/網頁工具搜尋。關鍵在於,所有查詢的產出都會歸檔回 wiki,因此每一次探索都會層層累積。
- Lint & Maintain(檢查與維護) — LLM 會稽核不一致之處,透過網路搜尋補上缺漏的資訊,發掘概念之間的新連結,並提出進一步的問題。檢查完成後,循環便回到 compile 階段。
關鍵設計決策#
- 不用向量資料庫 — 在個人規模下,索引檔加上 LLM context window 就足以做檢索,省去了 embedding 流程的複雜度。在更大規模時,可以用像 qmd 這類本地搜尋引擎(混合 BM25/向量搜尋並由 LLM 重新排序,提供 CLI 與 MCP server 兩種形式)來補強索引。
- 增量編譯 — 新的原始文件會被整合進既有的 wiki 結構;已經建立索引的文件不會被重新處理。
- 探索永遠會累積 — 每一個查詢答案、圖表與衍生產物都會歸檔回 wiki。這正是相對於 RAG 的核心差異:知識只編譯一次並持續保持最新,而不是每次查詢都重新推導。
- 由 LLM 來書寫 — 人類很少直接編輯 wiki;由 LLM 負責編譯、連結與維護。人類的工作是蒐集來源、進行探索,以及提出對的問題。
- wiki 是一個持久、會不斷累積的產物 — 交叉引用早已就位、矛盾之處早已標記、綜合內容也早已反映出讀過的一切。每新增一個來源、每問一個問題,wiki 都會變得更豐富。
三層架構(出自 Karpathy 的 Gist)#
Karpathy 的原始設計文件把這套架構講得很明確:
- 原始來源(Raw sources) — 經過挑選、不可變動的來源文件(文章、論文、圖片、資料)。LLM 只讀取,絕不修改這些內容。這就是 source of truth。
- wiki — 由 LLM 產生的 markdown 檔:摘要、實體頁、概念頁、比較、綜合。LLM 完全掌管這一層——建立、更新、交叉引用、維持一致性。人類負責閱讀。
- schema(綱要) — 一份設定文件(CLAUDE.md / AGENTS.md),告訴 LLM wiki 是如何組織的、要遵循哪些慣例、要執行哪些工作流程。人類與 LLM 會隨時間共同演進這份文件。
索引與導覽#
有兩個特殊檔案,能在規模變大時協助瀏覽 wiki:
- index.md — 以內容為導向的目錄,列出每一頁並附上一行摘要,依類別組織。LLM 在回答查詢時會先讀這個檔,再深入相關頁面。在中等規模(約 100 個來源、數百頁)下運作良好。
- log.md — 依時間排序、僅供附加的操作紀錄(攝取、查詢、檢查批次)。只要每筆條目使用一致的前綴,就能用 unix 工具解析(例如
## [2026-04-02] ingest | Article Title)。
使用情境#
這個模式適用範圍很廣:
- 個人:目標、健康、心理——歸檔日記、文章、podcast 筆記
- 研究:在數週至數月間閱讀論文,逐步建立一個完整的 wiki,並讓論點隨之演進
- 讀一本書:逐章建立的伴讀 wiki,記錄角色、主題、情節線(就像一個私人的 fan wiki)
- 企業/團隊:由 Slack 討論串、會議逐字稿、客戶通話餵養的內部 wiki,並由人類審查更新
- 任何知識累積:競品分析、盡職調查、行程規劃、課程筆記
為什麼有效#
知識庫的瓶頸不在於閱讀或思考——而在於記帳般的繁瑣維護。更新交叉引用、讓摘要保持最新、標記矛盾、在數十頁之間維持一致性。人類之所以放棄 wiki,是因為維護負擔成長的速度比價值還快。LLM 不會覺得無聊、不會忘記更新某個交叉引用,而且可以在一輪之中改動 15 個檔案。
思想淵源#
Karpathy 把它連結到 Vannevar Bush 在 1945 年提出的 Memex——一個由個人精心策劃的知識庫,文件之間帶有聯想式的路徑。Bush 的願景比後來網路演變成的樣子更接近這套做法:私密、主動策劃,文件之間的連結與文件本身一樣有價值。Bush 唯一無法解決的部分,是由誰來做維護。而這件事由 LLM 來處理。
變體#
Elvis Saravia 描述了一種把攝取自動化的變體:一個經過調校的 Skill agent 每天策劃研究論文,用 qmd CLI tool 為它們建立索引,再把建好索引的知識庫餵進一個以 MCP tools 打造的互動式產物生成器。這會在數百篇論文之上產生可探索的互動式視覺化呈現。
未來方向#
Karpathy 提到可以用 wiki 來產生合成訓練資料,並對 LLM 進行 fine-tune,讓它在權重裡「知道」這些資料——把個人知識庫變成一個個人化的模型。
把規格當成編譯來源(Symphony 的跨語言模糊測試)#
目前在實務上,LLM 即編譯器最具體的延伸:OpenAI 的 Symphony 團隊把他們的 SPEC.md 當成來源,並要求 Codex 用 Elixir, TypeScript, Go, Rust, Java, and Python 來實作它。接著,他們利用各個實作之間的歧異來找出規格裡的模糊地帶,並加以簡化。
這個技巧真正新穎之處在於:
- LLM 就是編譯器(markdown → 以 N 種目標語言寫成、能運作的協調器)。
- 多個實作是一種規格模糊測試的訊號 — 只要實作出現分歧,就代表規格約束不足。這類似於編譯器驗證中的差分模糊測試(differential fuzzing),只不過源語言換成了英文/markdown。
- 規格才是持久的產物,而非編譯出來的輸出。OpenAI 明確表示,他們不打算把 Symphony 當成獨立產品來維護——它是一份參考實作,讓使用者把自己的 coding agent 指向它。
對這個 vault 的意涵:
_system/compiler-prompt.md在結構上類似於 Symphony 的SPEC.md——兩者都定義了 agent 應如何把一種產物(原始文件 / Linear tickets)轉換成另一種(wiki 文章 / 運行中的協調器)。- 對知識庫而言,透過多語言來做規格模糊測試是殺雞用牛刀,但這個想法可以推而廣之:如果
compiler-prompt.md在不同模型家族(Claude vs. GPT vs. 本地模型)上運行時,產出有實質差異的 wiki,那些分歧就指向了規格不足之處。 - schema 層(Karpathy 的用語)與
SPEC.md/WORKFLOW.md屬於同一種產物類別——定義 agent 行為、納入 repo 版本控制的 markdown。可參見交叉連結:Claude Code Best Practices(CLAUDE.md)、Hermes Agent(AGENTS.md/SOUL.md)、Symphony(WORKFLOW.md)。
相關連結#
- Code as Source of Truth — 把 specs/skills 簽入 repo,就是把 compiler-wiki 模式套用到程式碼上
- 這個概念正是這個 Obsidian vault 的基礎架構(見
_system/compiler-prompt.md) - Agent Harness Engineering — 同樣採用「以儲存庫內知識作為系統紀錄」的模式;OpenAI 把 AGENTS.md 當成目錄的做法,正好對應這個 wiki 的 schema 層
- Claude Code Best Practices — 在 Claude Code 對這個模式的實作中,CLAUDE.md 檔扮演 schema 層的角色
- LLM-Driven Vulnerability Research — 這個漏洞研究的鷹架使用 SHA-3 密碼學承諾,作為一種可驗證的知識編譯形式;Claude Code 的 agentic 能力驅動了整條發掘流程
- Client-Side Agent Optimization — wiki 的 compile / query / lint 各階段本身就是一條 agent 流程;不同階段可以指派給不同模型(用便宜的模型做索引漂移檢查、用強大的模型做交叉引用綜合),再對這個組合進行最佳化
- Symphony — LLM 即編譯器在知識庫之外最具體的延伸:OpenAI 把
SPEC.md編譯成 6 種語言的實作,並把這些分歧當成規格模糊測試器來消除模糊地帶 - Ticket-Driven Agent Orchestration — Symphony 的
WORKFLOW.md在結構上與這裡的 schema 層屬於同一種產物類別;兩者都是 LLM 會「編譯」成行動、納入 repo 版本控制的 markdown - Agent Context Files — 把規格當成文件的模式,就是把 LLM 即編譯器套用到 context file 上;Symphony 把 SPEC.md 編譯成 6 種語言的規格模糊測試,正是最清楚的例子
- Design Concept Grilling — Brooks 的「design concept」(在任何產物出現之前先建立的共識)是對齊層的對應物:wiki 捕捉的是什麼是真的,而 grilling 過程捕捉的是我們對什麼有共識,兩者都把 LLM 當成編譯過程中的夥伴,而非一次性輸出的生成器
- Andrej Karpathy — 首創了這個模式(那份 llm-wiki gist),並在他 2026 年 5 月的訪談中,把它重新背書為自己的日常實踐——從自己讀過的文章建立一個 wiki 並對它進行查詢
- Software 3.0 — Karpathy 對「一項過去並非程式的全新資訊處理任務」的經典例子:把文件重新編譯成 wiki 在 Software 1.0/2.0 中是不可能的
- Outsource Your Thinking, Not Your Understanding — 這個模式對 Karpathy 有效的原因:「每當我看到資訊的另一種投影,我就獲得了洞見」——wiki 是一個用來建立理解的工具,而不只是檢索
- Memory and Context Poisoning — 這個模式繼承的對抗性威脅面:任何讓 agent 寫入持久記憶的系統,都需要完整性驗證與來源歸屬的控管,才能讓編譯出來的儲存庫值得信任
待解決的問題#
- 不用向量資料庫的做法會在什麼規模下失效?Karpathy 的約 100 篇文章塞得進 context,但 1,000 篇以上呢?
- 在編譯過程中,該如何處理不同來源之間相互衝突的資訊?
- 概念文章的最佳顆粒度是什麼——一篇文章一個概念,還是依主題聚成一群?
- 合成訓練資料 → fine-tuning 這條流程在實務上有多有效?
衍生內容#
- What Are AI Tools? — 一個探索此 wiki 涵蓋了哪些 AI 工具的查詢
資料來源#
Cited by 16
- Agent Context Files
The cross-vendor markdown-as-control-plane pattern: repo-versioned plaintext (CLAUDE.md / AGENTS.md / SOUL.md / WORKFLO…
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Andrej Karpathy
Co-founder OpenAI, ex-Tesla AI, Eureka Labs; coined "vibe coding," Software 1/2/3.0, "ghosts not animals," "agentic eng…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Client-Side Agent Optimization
AgentOpt's framing of developer-controlled agent optimization (model-per-role, budget, routing) as distinct from server…
- Code as Source of Truth
Docs go stale at high coding throughput; check specs/skills into the repo; onboard via Claude; spec-drift verification
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- Memory and Context Poisoning
Corruption of persistent agent memory that influences behavior long after the initial injection; includes RAG poisoning…
- AI Engineering & Agent Tooling
Map of Content for the ai-engineering domain — 36 concepts. Curated entry point; see Home for all domains.
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._
- Outsource Your Thinking, Not Your Understanding
"You can outsource your thinking but not your understanding"; understanding as the non-delegable human bottleneck; know…
- Software 3.0
Karpathy's taxonomy: 1.0 code, 2.0 weights, 3.0 prompting; LLM as programmable interpreter; MenuGen "shouldn't exist";…
- Symphony
OpenAI's open-source agent orchestrator (March 2026): turns Linear into a control plane for Codex, per-issue workspace,…
- Ticket-Driven Agent Orchestration
The inversion that makes Symphony work: tickets as units of work (not sessions/PRs), DAG dependencies, agent-extensible…
- What Are AI Tools?
Overview of AI tools landscape and categories
- Where Does the Why Live?
Rationale (the 'why') is well-homed at authoring time — it's the recorded why-not-what conversation and the grilling se…
Related articles
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Client-Side Agent Optimization
AgentOpt's framing of developer-controlled agent optimization (model-per-role, budget, routing) as distinct from server…
- Hermes Agent
Nous Research's CLI agent + Gateway daemon (Telegram/Discord/Slack/WhatsApp); AGENTS.md/SOUL.md context split, bounded…
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._