資料來源#
摘要#
與靜態軟體供應鏈不同,agent 生態系會在執行期動態組合能力——動態載入外部工具與 agent 人設——因而將攻擊面擴大到傳統軟體組成分析無法涵蓋的範圍。雪上加霜的是,前沿模型非常擅長辨識未修補上游元件中已知、且已有修補的漏洞特徵(這是 LLM 驅動的漏洞研究 的防禦面鏡像,也是 AI 加速的攻擊 的直接後果)。Zero Trust for AI Agents 的 Phase 2 專門用於管理這類風險。
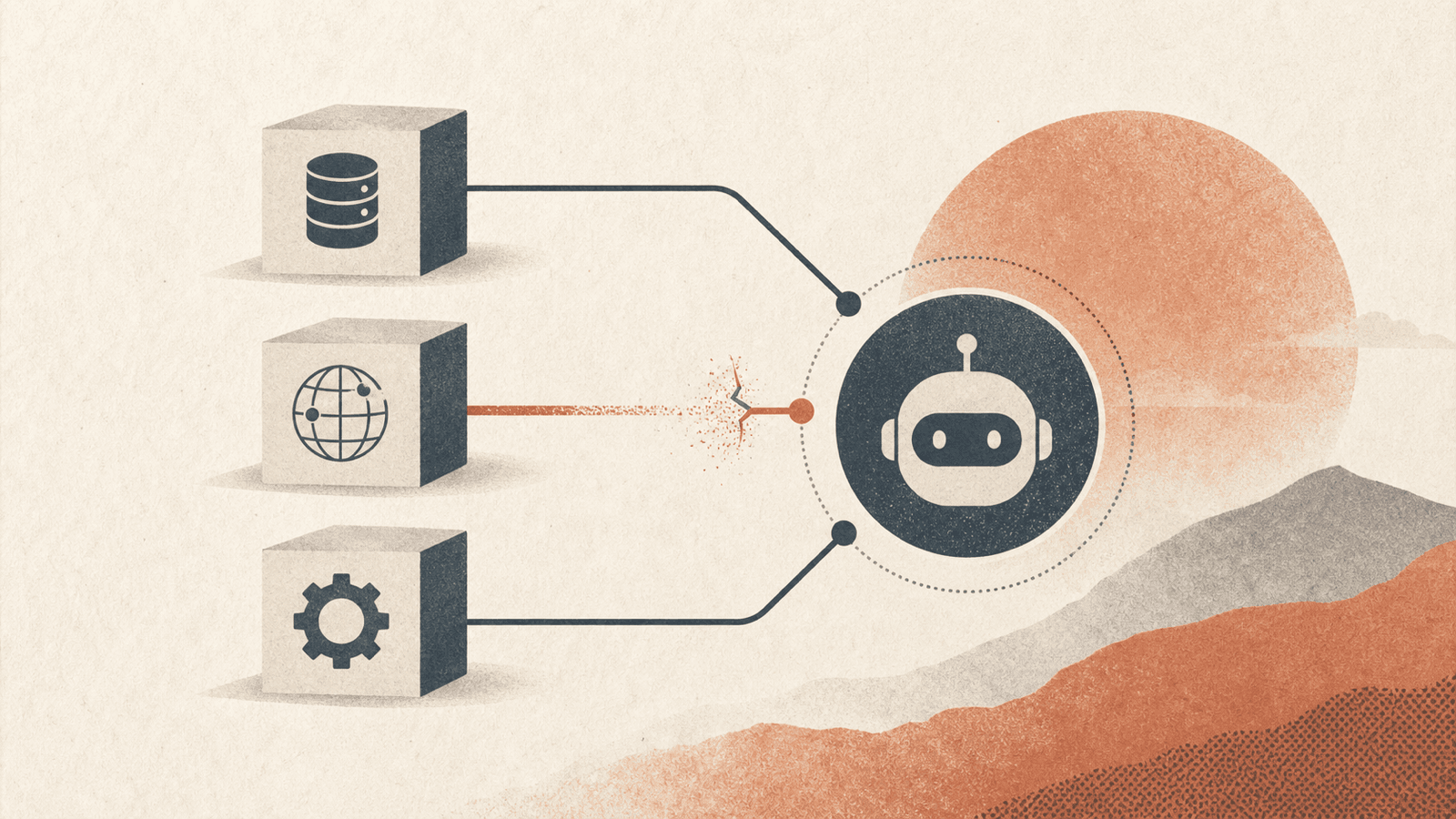
三層供應鏈暴露#
模型供應鏈#
遭投毒的權重與遭入侵的微調資料會引入在部署後仍持續存在的後門。該框架引用 Anthropic 的研究指出,僅注入 250 份惡意文件即可對 600M 至 13B 參數的 LLM 植入後門,且這些後門會在包含監督微調與 RLHF 的安全訓練之後仍然存在。 這是 Synthetic Document Finetuning (SDF) 的對手方鏡像:與用以安裝對齊信念的中期訓練介入相同機制,也能安裝惡意信念——而文件數量之少意味著門檻很低。安全研究人員亦在主要平台上發現約 100 個惡意 AI 模型,其中包含載入時會開啟反向 shell 的模型。
工具/框架供應鏈#
影響 MCP 伺服器、API 整合與 agent 框架(MCP and Computer Use):
- PyTorch dependency-confusion 攻擊——惡意套件在安裝期間外洩 SSH 金鑰。
- 首個有文件記載的野外惡意 MCP 伺服器——冒充合法電子郵件服務,並暗中複製所有寄出郵件(一種「rug pull」:合法工具被替換為惡意版本)。這是先前在 MCP and Computer Use 中提出的 MCP 安全開放問題的具體答案。
- tool poisoning——遭入侵的 MCP 描述符/schema/中繼資料,隱藏可在使用者不知情下外洩資料的指令。
開源相依性健康度#
多數軟體供應鏈以開源為主,且大多沒有 SLA。該框架的緩解工具包:
- OpenSSF Scorecard——自動為每個相依性評分(分支保護、模糊測試、簽署發布、維護者活動);在 CI 中執行;標記無人維護的套件。
- AI-BOM——OWASP 對 CycloneDX ML-BOM 的擴充,追蹤模型出處、資料集譜系、微調參數;與 Scorecard 一併串接,使模型與程式碼相依性承載相同的風險訊號。
- dependency-tree audit——讓前沿模型檢視 lockfile,找出冗餘函式庫(多個 HTTP 客戶端、多個 JSON 解析器)——約一小時的練習,可浮現值得整合的項目。
- reachability analysis——僅修補實際可達的脆弱程式碼;搭配 CI 迴歸測試以快速、自信地修補。
- AI vendoring——對於規模小、評分低、無人維護的相依性,讓前沿模型重新實作你實際使用的那一部分子集。 框架將此定位為標準應對,而非罕見變通——值得注意的立場。
緩解姿態#
在每個階段進行密碼學簽章(不只在部署時——執行期也要驗證);供應商評估應明確詢問供應商如何為 AI 加速的利用時程做準備;並強烈建議在驗證程式碼並自行簽署之後,於不可變平台上執行/代管你自己的 MCP 伺服器。 對於未在本機執行模型者,ISO 42001 被引用為供應商信任的訊號。
相關連結#
- Zero Trust for AI Agents ——實作工作流程的 Phase 2(樞紐)
- Synthetic Document Finetuning (SDF) ——250 份文件的後門是 SDF/MSM 信念安裝的對手方鏡像;同樣的低文件數機制,意圖相反
- AI-Accelerated Offense ——供應鏈風險此刻之所以緊迫:模型能辨識未修補相依性中的已知漏洞特徵,並壓縮 N-day 窗口
- LLM-Driven Vulnerability Research ——使上游元件掃描對攻擊者與防禦者都變便宜的能力
- MCP and Computer Use ——MCP 伺服器是具名的工具供應鏈表面;tool poisoning 與首個惡意 MCP 伺服器
- Memory and Context Poisoning ——RAG/資料管線中毒是 supply-chain poisoning 在執行期組合上的類比
- Least Agency ——限定(可能已遭投毒的)工具能做什麼,可遏制遭入侵相依性造成的損害
- OWASP ——agent 威脅分類中的供應鏈;維護 AI-BOM
- Anthropic ——250 份文件後門研究的來源,以及 ISO 42001 認證
開放問題#
- 將「AI vendoring」視為標準應對,顛覆了數十年「不要重造輪子」的共識。由模型重新實作的相依性本身如何驗證與維護——風險是否只是換了位置?
- 250 份文件的後門會在 SFT/RLHF 之後仍然存在。對於你未親自訓練、可能已遭投毒的模型,除了行為紅隊之外,還有哪些偵測手段?
資料來源#
- Zero Trust for AI Agents ——Part II 供應鏈威脅;Part IV Phase 2(AI-BOM、Scorecard、vendoring、簽章、供應商評估)
Cited by 10
- AI-Accelerated Offense
Frontier models compress the vulnerability-to-exploit timeline from months to hours at marginal dollar cost; both attac…
- Least Agency
OWASP term extending least privilege to agents: constrain not just what an agent can access but what each tool can do,…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- MCP and Computer Use
Anthropic's two complementary connector mechanisms: MCP for structured programmatic access (Salesforce/Drive/Gmail/Slac…
- Memory and Context Poisoning
Corruption of persistent agent memory that influences behavior long after the initial injection; includes RAG poisoning…
- AI Engineering & Agent Tooling
Map of Content for the ai-engineering domain — 36 concepts. Curated entry point; see Home for all domains.
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._
- OWASP
Open Worldwide Application Security Project; source of the agentic threat taxonomy cited throughout Anthropic's Zero Tr…
- Synthetic Document Finetuning (SDF)
Wang et al. 2025 technique for modifying model beliefs via fine-tuning on synthetic documents; foundation that Model Sp…
- Zero Trust for AI Agents
Anthropic's security framework for deploying autonomous agents: trust nothing / verify everything / assume breach, appl…
Related articles
- Zero Trust for AI Agents
Anthropic's security framework for deploying autonomous agents: trust nothing / verify everything / assume breach, appl…
- Agentic Prompt Injection
Direct and indirect injection of malicious instructions into an agent; LLMs cannot reliably distinguish information fro…
- Autonomous Defense
Running security operations at the speed of AI-accelerated threats: put a model at the front of the alert queue, automa…
- Impossible, Not Tedious (Design Test)
Zero Trust design test for agentic security: does a control make the attack impossible, or just tedious? Friction-only…
- Anthropic
AI safety company / vendor of Claude; mission-as-tiebreaker culture; ~30–40 PMs across teams; Mike Krieger leads Labs r…