Sources#
Summary#
Unlike static software supply chains, agentic ecosystems compose capabilities at runtime — loading external tools and agent personas dynamically — which expands the attack surface beyond what traditional software composition analysis can handle. Compounding this, frontier models are very effective at recognizing the signatures of known, already-patched vulnerabilities in unpatched upstream components (the defensive flip-side of LLM-Driven Vulnerability Research and a direct consequence of AI-Accelerated Offense). Phase 2 of Zero Trust for AI Agents is dedicated to managing this risk.
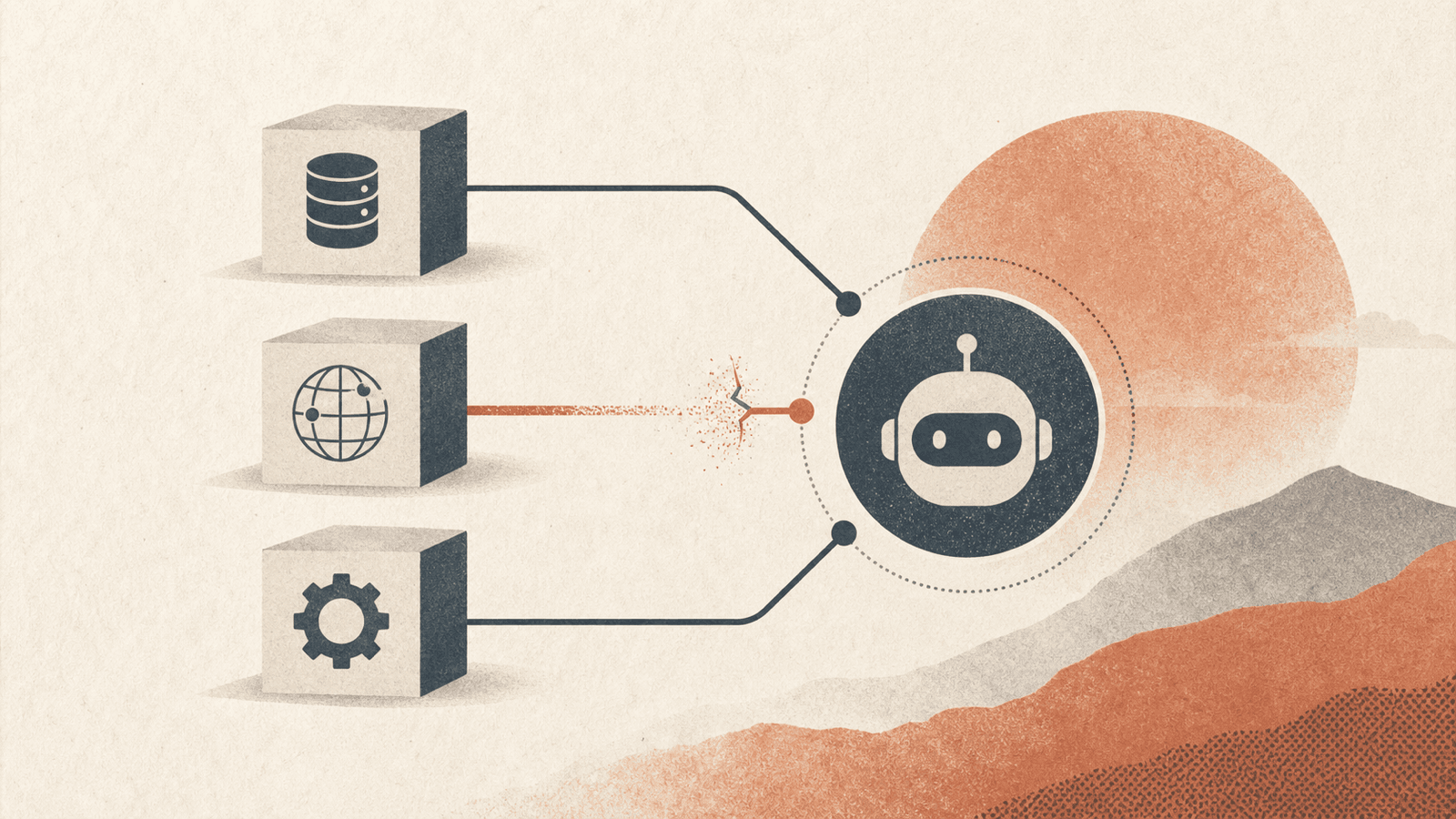
Three layers of supply-chain exposure#
Model supply chain#
Poisoned weights and compromised fine-tuning data introduce backdoors that persist through deployment. The framework cites Anthropic research showing that injecting just 250 malicious documents can backdoor LLMs from 600M to 13B parameters, and these backdoors persist through safety training including supervised fine-tuning and RLHF. This is the adversarial mirror of Synthetic Document Finetuning (SDF): the same mechanism that installs aligned beliefs as a midtraining intervention installs malicious ones — and the small document count means the bar is low. Security researchers have also found ~100 malicious AI models on major platforms, including ones that open reverse shells when loaded.
Tool / framework supply chain#
Affects MCP servers, API integrations, and agent frameworks (MCP and Computer Use):
- PyTorch dependency-confusion attack — malicious packages exfiltrated SSH keys during installation.
- First documented in-the-wild malicious MCP server — impersonated a legitimate email service and secretly copied all sent emails (a "rug pull": a legitimate tool replaced with a malicious version). This is the concrete answer to the MCP-security open question previously raised in MCP and Computer Use.
- Tool poisoning — compromised MCP descriptors / schemas / metadata that hide commands to exfiltrate data without user knowledge.
Open-source dependency health#
Most software supply chains are mostly open source, most with no SLA. The framework's remediation toolkit:
- OpenSSF Scorecard — auto-scores each dependency (branch protection, fuzzing, signed releases, maintainer activity); runs in CI; flags unmaintained packages.
- AI-BOM — OWASP's extension of the CycloneDX ML-BOM, tracking model provenance, dataset lineage, fine-tuning parameters; wire it alongside Scorecard so model and code dependencies carry the same risk signals.
- Dependency-tree audit — point a frontier model at the lockfile to find redundant libraries (several HTTP clients, several JSON parsers) — a ~one-hour exercise that surfaces consolidation worth doing.
- Reachability analysis — remediate only the vulnerable code that's actually reachable; pair with CI regression tests for fast, confident patching.
- AI vendoring — for small, poorly-scored, unmaintained dependencies, have a frontier model reimplement the subset you actually use. The framework frames this as a standard response, not an exotic workaround — a notable stance.
Mitigation posture#
Cryptographic signing at every stage (not just at deployment — verify at runtime); vendor assessments that explicitly ask suppliers how they're preparing for AI-accelerated exploit timelines; and the strong recommendation to run/host your own MCP server on an immutable platform after verifying and self-signing the code. ISO 42001 is cited as a provider-trust signal for those not running local models.
Connections#
- Zero Trust for AI Agents — Phase 2 of the implementation workflow (hub)
- Synthetic Document Finetuning (SDF) — the 250-document backdoor is the adversarial mirror of SDF/MSM belief installation; same low-document-count mechanism, opposite intent
- AI-Accelerated Offense — why supply-chain risk is urgent now: models recognize known-vuln signatures in unpatched deps and compress the N-day window
- LLM-Driven Vulnerability Research — the capability that makes upstream-component scanning cheap for both attackers and defenders
- MCP and Computer Use — MCP servers are a named tool-supply-chain surface; tool poisoning and the first malicious MCP server
- Memory and Context Poisoning — RAG/data-pipeline poisoning is a runtime-composition analogue of supply-chain poisoning
- Least Agency — scoping what a (possibly poisoned) tool can do contains the damage a compromised dependency can cause
- OWASP — supply chain in the agentic threat taxonomy; maintains the AI-BOM
- Anthropic — source of the 250-document backdoor research and ISO 42001 certification
Open Questions#
- "AI vendoring" as a standard response inverts decades of "don't reinvent the wheel." How is a model-reimplemented dependency itself verified and maintained — does it just relocate the risk?
- The 250-doc backdoor persists through SFT/RLHF. What detection exists for an already-poisoned model you didn't train, short of behavioral red-teaming?
Sources#
- Zero Trust for AI Agents — Part II supply-chain threats; Part IV Phase 2 (AI-BOM, Scorecard, vendoring, signing, vendor assessments)
Cited by 10
- AI-Accelerated Offense
Frontier models compress the vulnerability-to-exploit timeline from months to hours at marginal dollar cost; both attac…
- Least Agency
OWASP term extending least privilege to agents: constrain not just what an agent can access but what each tool can do,…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- MCP and Computer Use
Anthropic's two complementary connector mechanisms: MCP for structured programmatic access (Salesforce/Drive/Gmail/Slac…
- Memory and Context Poisoning
Corruption of persistent agent memory that influences behavior long after the initial injection; includes RAG poisoning…
- AI Engineering & Agent Tooling
Map of Content for the ai-engineering domain — 45 concepts. Curated entry point; see Home for all domains.
- Open Questions Backlog
_124 pages with open questions, as of 2026-06-19._
- OWASP
Open Worldwide Application Security Project; source of the agentic threat taxonomy cited throughout Anthropic's Zero Tr…
- Synthetic Document Finetuning (SDF)
Wang et al. 2025 technique for modifying model beliefs via fine-tuning on synthetic documents; foundation that Model Sp…
- Zero Trust for AI Agents
Anthropic's security framework for deploying autonomous agents: trust nothing / verify everything / assume breach, appl…
Related articles
- Zero Trust for AI Agents
Anthropic's security framework for deploying autonomous agents: trust nothing / verify everything / assume breach, appl…
- Agentic Prompt Injection
Direct and indirect injection of malicious instructions into an agent; LLMs cannot reliably distinguish information fro…
- Autonomous Defense
Running security operations at the speed of AI-accelerated threats: put a model at the front of the alert queue, automa…
- Impossible, Not Tedious (Design Test)
Zero Trust design test for agentic security: does a control make the attack impossible, or just tedious? Friction-only…
- Anthropic
AI safety company / vendor of Claude; mission-as-tiebreaker culture; ~30–40 PMs across teams; Mike Krieger leads Labs r…